哈夫曼树(Huffman Tree)
1. 学习内容
1.4 哈夫曼树
参考http://data.biancheng.net/view/33.html
1.4.1 哈夫曼树相关的几个名词
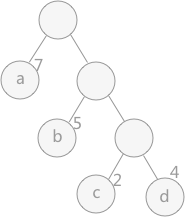
- 路径:在一棵树中,一个结点到另一个结点之间的通路,称为路径。图 1 中,从根结点到结点 a 之间的通路就是一条路径。
- 路径长度:在一条路径中,每经过一个结点,路径长度都要加 1 。例如在一棵树中,规定根结点所在层数为1层,那么从根结点到第 i 层结点的路径长度为 i - 1 。图 1 中从根结点到结点 c 的路径长度为 3。
- 结点的权:给每一个结点赋予一个新的数值,被称为这个结点的权。例如,图 1 中结点 a 的权为 7,结点 b 的权为 5。
- 结点的带权路径长度:指的是从根结点到该结点之间的路径长度与该结点的权的乘积。例如,图 1 中结点 b 的带权路径长度为 2 * 5 = 10 。
- 树的带权路径长度为树中所有叶子结点的带权路径长度之和。通常记作 “WPL” 。例如图 1 中所示的这颗树的带权路径长度为: WPL = 7 * 1 + 5 * 2 + 2 * 3 + 4 * 3
1.4.2 什么是哈夫曼树
当用 n 个结点(都做叶子结点且都有各自的权值)试图构建一棵树时,如果构建的这棵树的带权路径长度最小,称这棵树为“最优二叉树”,有时也叫“赫夫曼树”或者“哈夫曼树”。
在构建哈弗曼树时,要使树的带权路径长度最小,只需要遵循一个原则,那就是:权重越大的结点离树根越近。在图 1 中,因为结点 a 的权值最大,所以理应直接作为根结点的孩子结点。
1.4.3 构建哈夫曼树
对于给定的有各自权值的 n 个结点,构建哈夫曼树有一个行之有效的办法: 在 n 个权值中选出两个最小的权值,对应的两个结点组成一个新的二叉树,且新二叉树的根结点的权值为左右孩子权值的和; 在原有的 n 个权值中删除那两个最小的权值,同时将新的权值加入到 n–2 个权值的行列中,以此类推; 重复 1 和 2 ,直到所以的结点构建成了一棵二叉树为止,这棵树就是哈夫曼树。
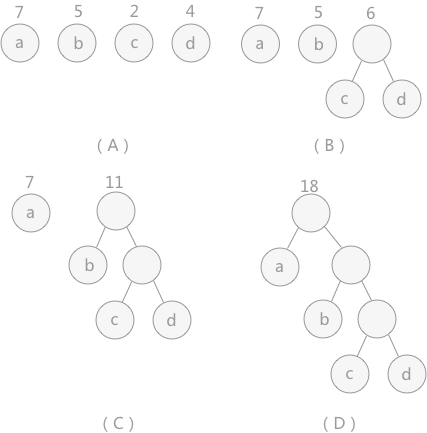
图 2 中,(A)给定了四个结点a,b,c,d,权值分别为7,5,2,4;第一步如(B)所示,找出现有权值中最小的两个,2 和 4 ,相应的结点 c 和 d 构建一个新的二叉树,树根的权值为 2 + 4 = 6,同时将原有权值中的 2 和 4 删掉,将新的权值 6 加入;进入(C),重复之前的步骤。直到(D)中,所有的结点构建成了一个全新的二叉树,这就是哈夫曼树。
1.4.4 哈夫曼编码
哈夫曼编码就是在哈夫曼树的基础上构建的,这种编码方式最大的优点就是用最少的字符包含最多的信息内容。
根据发送信息的内容,通过统计文本中相同字符的个数作为每个字符的权值,建立哈夫曼树。对于树中的每一个子树,统一规定其左孩子标记为 0 ,右孩子标记为 1 。这样,用到哪个字符时,从哈夫曼树的根结点开始,依次写出经过结点的标记,最终得到的就是该结点的哈夫曼编码。 文本中字符出现的次数越多,在哈夫曼树中的体现就是越接近树根。编码的长度越短。
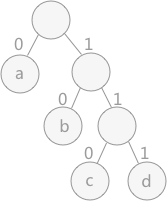
如图 3 所示,字符 a 用到的次数最多,其次是字符 b 。字符 a 在哈夫曼编码是 0 ,字符 b 编码为 10 ,字符 c 的编码为 110 ,字符 d 的编码为 111 。
举例频次。