Redundancy and fault tolerance - Internet
In the Internet Protocol (IP), computers split messages into packets and those packets hop from router to router on the way to their destination:

What happens if a network path is no longer available, like due to a natural disaster physically destroying it or a cybercriminal hijacking it? Is the packet doomed to never reach its destination?

Redundancy in routing
Fortunately, there are often many possible paths a packet can go down to reach the same destination. The availability of multiple paths increases the redundancy of a network.
Consider this simplified network connecting routers in four major cities:

There are multiple paths from the Oakland router to the New York router.
The first and shortest path goes from Oakland to Austin to New York:

A slightly longer path goes from Oakland to Austin to Tampa to New York:

Why is this redundancy so important? If the connection between the Austin and New York router is no longer available, then there’s still another way for the packet to reach its destination.

The redundancy of the paths in the network increases the number of possible ways that a packet can reach its destination.
[[☃ graded-group-set 1]]
Fault tolerance
A fault-tolerant system is one that can experience failure (or multiple failures) in its components, but still continue operating properly.
The Internet is a massive and complex system with millions of components that can break at any time—and many of those components do break. But as of 2020, nobody has managed to break the entire Internet.
A big contributor to the fault tolerance of the Internet is the redundancy in network routing paths.
Consider the number of underseas cables connecting the eastern side of the United States to the western side of Europe:
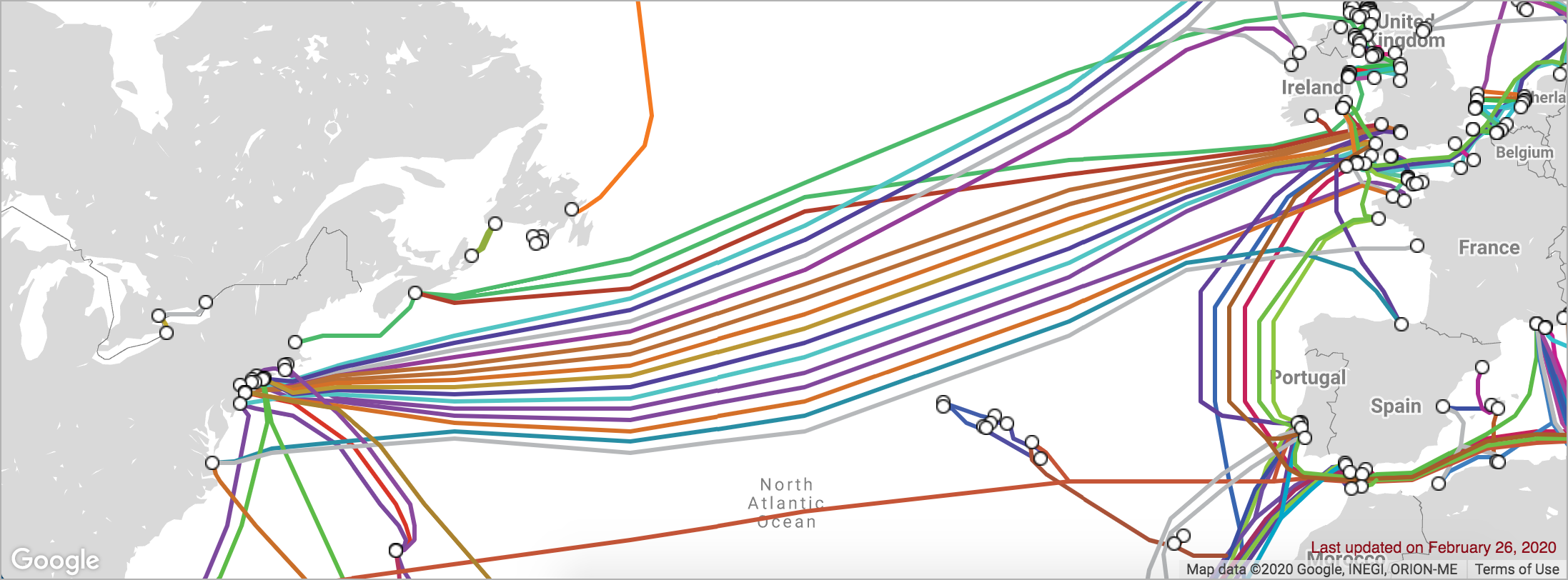
If one of those cables is damaged, there are multiple other cables that can carry Internet traffic over the Atlantic ocean.
Or, to put it another way, there is no single point of failure between the coasts. A single point of failure is a component in the system that will bring down the entire system if it fails. When we’re trying to make sure a system is fault tolerant, we look for single points of failure and find ways to add redundancy at those points.
Now consider the meager number of undersea cables between these Polynesian islands in the South Pacific:
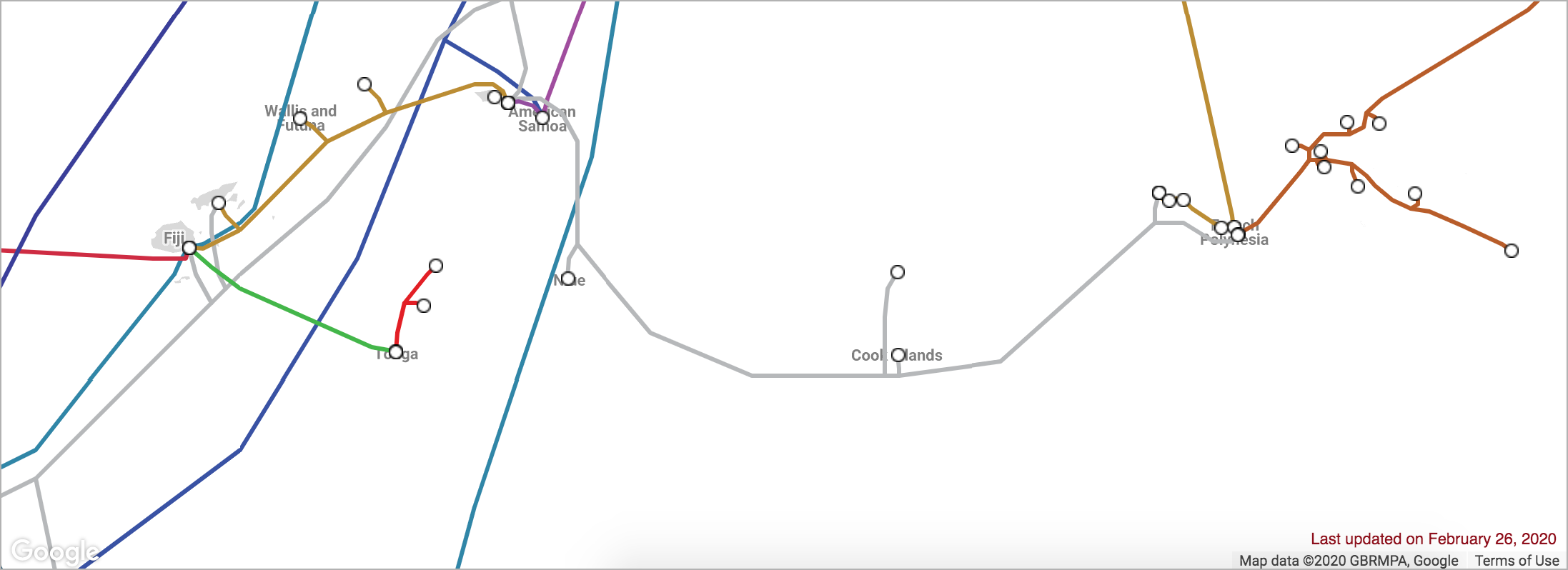
If a cable is cut between Cook Islands and French Polynesia, how will that affect the Internet on those islands?
In some cases, a cable cut can bring down an entire country. In 2019, a ship anchor dragging along the sea floor cut the cable to Tonga and cut their Internet access off for 11 days. ^1
It doesn’t take much to cut a cable. In 2011, a grandmother in the country of Georgia accidentally damaged a cable with her shovel, resulting in all of Armenia losing Internet access for 5 hours. ^2
Cable cuts happen relatively frequently—”around every 3 days”, according to networks analyst Stephan Beckert. ^3 Most of the time, the average Internet user doesn’t even notice when cuts happen and the cable gets fixed up by one of many cable repair ships. ^4 When we do notice the cable cuts, that usually means there’s a single point of failure and it’s time to add redundancy to the system.
Why don’t we start off with redundancy everywhere? As you might guess, it’s expensive. The underseas cable that connects Tonga to Fiji cost about $30 million, and that’s a relatively short cable. ^5 When Google installed a high speed fiber optic cable between the US and Tokyo, it cost $300 million dollars. ^6
When it’s too expensive to duplicate a resource, it may be possible to find ways for the system to gracefully degrade in the face of failure. During the Tonga outage, satellite providers rushed to provide Internet access. ^7 They may not have been able to provide the same speeds as the fiber cable connection, but any Internet connection is better than no Internet connection at all.
🤔 Consider the fault tolerance of the infrastructure around you. How much redundancy is in the electrical system of your home or computer lab? Are there any single points of failures? What would be the least expensive way to increase the redundancy? [[☃ explanation 2]]
The 1970 ARPANET was not very fault tolerant. With so few connections between nodes, a failure could easily disrupt the ARPANET.

If a computer wanted to send a message from Utah to BBN, which connections definitely needed to stay available?
A. Utah ↔ SRI
B. UCLA ↔ BBN
C. SRI ↔ UCSB
D. SRI ↔ UCLA
[[☃ explanation 1]]
本页面采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
致谢:Khan Academy - AP® Computer Science Principles