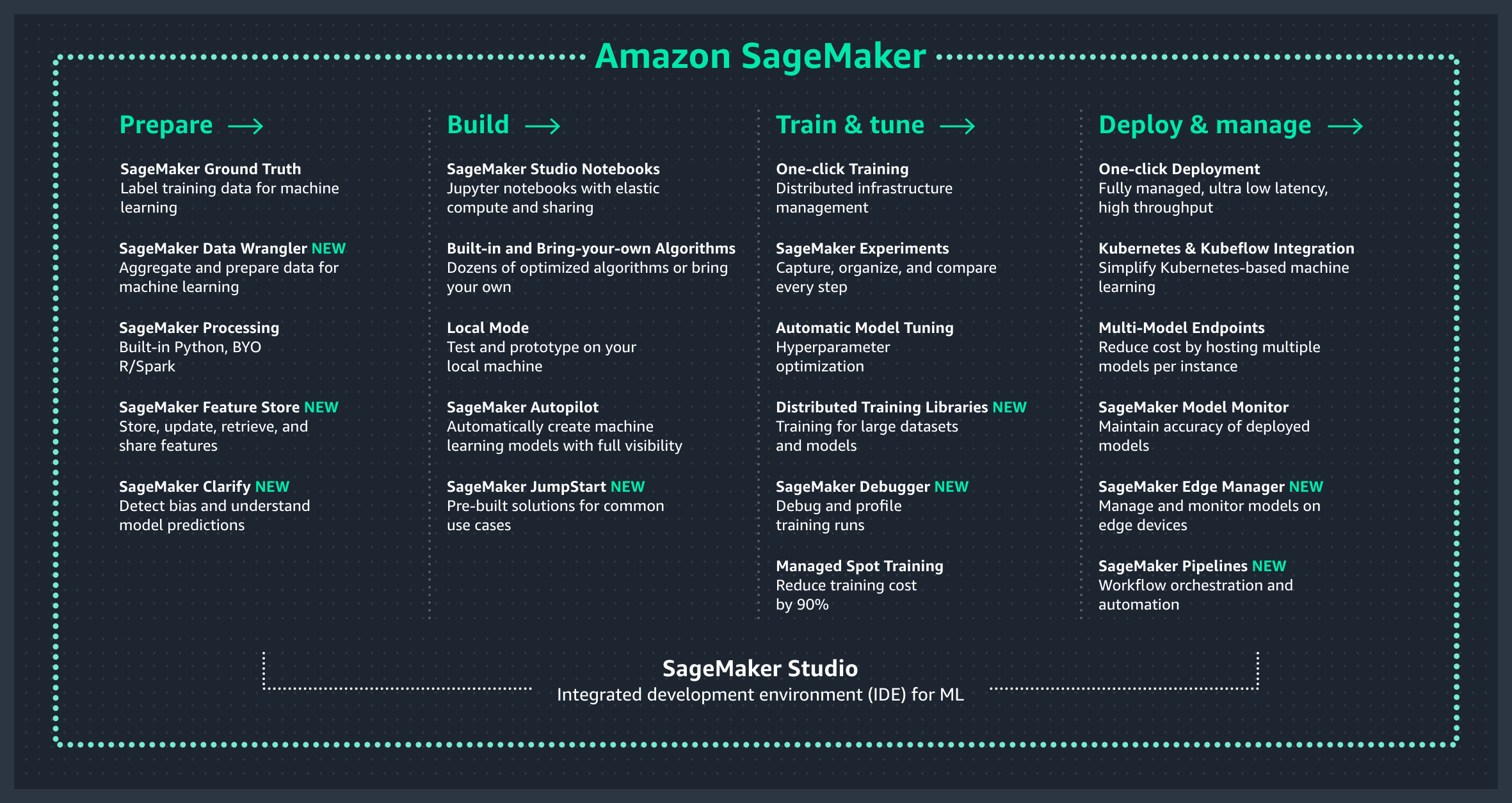
Amazon SageMaker(AWS机器学习平台)
借鉴点:基于用户群体做产品分类。
- Business Analysts(分析师): Make ML predictions using a visual interface with Amazon SageMaker Canvas.(无代码)
- Data Scientists(数据科学家): Prepare data, build, train, and deploy ML models using Amazon SageMaker Studio.(效率工具)
- MLOps Engineers(工程师): Deploy and manage models at scale with Amazon SageMaker MLOps.(发布和管理)
概览
Amazon SageMaker is a fully managed service that provides every developer and data scientist with the ability to build, train, and deploy ML models at scale. It removes the complexity from each step of the ML workflow so you can more easily deploy your ML use cases, anything from predictive maintenance to computer vision to predicting customer behaviors.
Amazon SageMaker is an ML service enabling data scientists, data engineers, MLOps engineers, and business analysts to build, train, and deploy ML models for any use case, regardless of ML expertise.
数据科学家 - SageMaker Studio
见:Amazon SageMaker for Data Scientists
Integrated development environment (IDE) for the ML lifecycle
主要用户群体:Data Scientists(数据科学家)
Data science is the study of data to extract meaningful insights for business. It asks and answers questions like what happened, why it happened, and what will happen. Machine learning (ML) is essential for data science because ML makes it practical for machines to solve problems that traditional analytics cannot easily solve with rule-based logic. ML analyzes data and discovers patterns by learning from examples. Machines can then use the patterns to recognize unknown instances. Amazon SageMaker offers a broad set of ML capabilities used by tens of thousands of customers to access and analyze data, and build, train, and deploy high-quality ML models. Your data science teams can be up to 10x more productive using Amazon SageMaker.
How it works
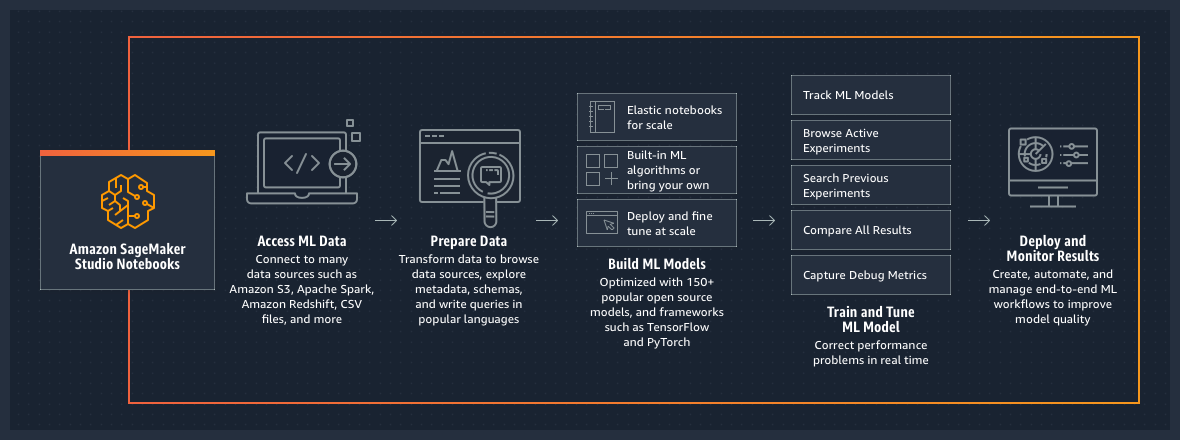
Prepare
Prepare data for ML in minutes(SageMaker Data Wrangler)
参考Amazon SageMaker Data Wrangler: The fastest and easiest way to prepare data for machine learning
- Prepare data for ML in minutes:
- Select and query data with just a few clicks
- Easily transform data
- Understand your data with visualizations
- Quickly estimate ML model accuracy
- Diagnose and fix ML data preparation issues faster
- From preparation to production with a single click
- Automate ML data preparation workflows
With SageMaker Data Wrangler’s data selection tool, you can quickly select data from multiple data sources, such as Amazon Athena, Amazon Redshift, AWS Lake Formation, Amazon S3, and the Amazon SageMaker Feature Store. You can write queries for data sources and import data directly into SageMaker from various file formats, and use SageMaker Data Wrangler’s visualization templates and built-in data transforms to ensure data prepared will result in accurate ML models.
功能点:
- 从多个数据源选择,包括特征库
- 写查询语句
- 可视化模板
- 数据转换
Low latency feature store(SageMaker Feature Store 特征库)
参考Amazon SageMaker Feature Store: A fully managed repository for machine learning features
- Search and discovery
- Ensure Feature Consistency
- Feature standardization
A fully managed repository to store, update, retrieve, and share machine learning features, SageMaker Feature Store serves the exact same features in batch for training and in real-time for inference so you don’t need to write code to keep features consistent. You can easily add new features, update existing ones, retrieve features in batches for training, and get the same features with single-digit millisecond latency for real-time inference.
Scalable data preparation using notebooks(SageMaker Studio - Notebooks)
可以使用Spark
You can visually browse, discover, and connect to Apache Spark data processing environments running on Amazon EMR from your SageMaker Studio notebooks with a few clicks. Once connected, you can interactively query, explore, and visualize data, and run Spark jobs using the language of your choice (SQL, Python, and Scala) to build end-to-end data preparation and ML workflows.
Data Labeling
Amazon SageMaker data labeling allows you to identify raw data, such as images, text files, and videos, and add informative labels to create high-quality training datasets for your machine learning models.
Build
One-click Jupyter Notebooks(一键启动Notebooks)
Amazon SageMaker Studio Notebooks are one-click Jupyter Notebooks that can be spun up quickly. The underlying compute resources are fully elastic, so you can easily dial up or down the available resources and the changes take place automatically in the background without interrupting your work. Notebooks can be shared with a single click, your colleagues get the exact same notebook, saved in the same place.
Built-in algorithms(容器中预置算法)
Amazon SageMaker offers over 15 built-in algorithms available in pre-built container images that can be used to quickly train and run inference.
Pre-built solutions and open-source models(SageMaker JumpStart 预置模型)
参考Amazon SageMaker JumpStart: Pre-built machine learning (ML) solutions that you can deploy with just a few clicks
Amazon SageMaker JumpStart helps you quickly get started with ML using pre-built solutions that can be deployed with just a few clicks. SageMaker JumpStart also supports one-click deployment and fine-tuning of more than 150 popular open-source models.
Optimized for major frameworks(针对主流深度学习框架的优化)
Amazon SageMaker is optimized for many popular deep learning frameworks such as TensorFlow, Apache MXNet, PyTorch, and more. Frameworks are always up-to-date with the latest version, and are optimized for performance on AWS. You don’t need to manually setup these frameworks and can use them within the built-in containers.
Train
Detect bias and understand predictions(SageMaker Clarify 检测偏移、理解模型)
参考Amazon SageMaker Clarify: Detect bias in ML models and understand model predictions
- Detect bias in your data and model(检测数据和模型的偏移)
- Identify imbalances in data(数据的偏移)
- Check your trained model for bias(检查训练好的模型的偏移)
- Monitor your model for bias(监控模型的偏移)
- Explain model behavior(模型的解释)
- Understand your model
- Monitor your model for changes in behavior
- Explain individual model predictions
Amazon SageMaker Clarify provides data to improve model quality through bias detection during data preparation and after training. SageMaker Clarify also provides model explainability reports so stakeholders can see how and why models make predictions.
Organize, track, and evaluate training runs(SageMaker Experiments 训练过程的记录)
Amazon SageMaker Experiments automatically captures training input parameters, configurations, and results, and stores them as ‘experiments’. You can browse active experiments, search for previous experiments by their characteristics, review previous experiments with their results, and compare experiment results visually.
Detect and debug problems(SageMaker Debugger)
Amazon SageMaker Debugger captures metrics in real-time so you can correct performance problems quickly before the model is deployed to production.
Deploy
Continuously monitor model(SageMaker Model Monitor 模型监控)
参考Amazon SageMaker Model Monitor: Keep machine learning models accurate over time
Amazon SageMaker Model Monitor automatically detects model and concept drifts and provides detailed alerts that help identify the source of the problem so you can improve model quality over time. All models trained in SageMaker automatically emit key metrics that can be collected and viewed in SageMaker Studio.
Easy Deployment Options(SageMaker Deployment 模型部署)
参考Amazon SageMaker Deployment: Easily deploy and manage machine learning models at scale
Amazon SageMaker provides the broadest selection of machine learning (ML) infrastructure and model deployment options meeting the needs of your use case, whether real-time or batch, so you can easily deploy your ML models at scale. SageMaker supports the entire spectrum of inference requirements ranging from low latency (a few milliseconds) and high throughput (hundreds of thousands of inference requests per second), to long-running inference for use cases such as natural language processing (NLP) and computer vision (CV).
分析师 - SageMaker Canvas(无代码)
主要用户群体:business analysts(分析师)
Generate accurate machine learning predictions — no code required.
How it works(产品流程)
Amazon SageMaker Canvas expands access machine learning (ML) by providing business analysts with a visual point-and-click interface that allows them to generate accurate ML predictions on their own — without requiring any machine learning experience or having to write a single line of code.

Features(功能)
- Browse, import, and join data
- Built-in data cleansing and data adjustments
- Model preview
- Automatic prediction creation
- Built-in sharing
Benefits(产品亮点)
- Generate ML predictions without writing code(无代码)
- SageMaker Canvas provides a visual point-and-click interface for business analysts to build ML models and generate accurate predictions without writing code or having any previous ML experience.
- Quickly access and prepare data for ML(数据源)
- With SageMaker Canvas, you can quickly connect and access data from cloud and on-premises data sources, combine datasets, and create unified datasets for training ML models. SageMaker Canvas automatically detects and corrects data errors and analyzes data readiness for ML.
- Use built-in AutoML to generate predictions(AutoML)
- SageMaker Canvas uses powerful AutoML technology from Amazon SageMaker to automatically create ML models based on your unique use case. This allows SageMaker Canvas to identify the best model based on your dataset so you can generate accurate preditions—whether singular or in bulk.
- Validate ML models with data scientists(和SageMaker Studio集成,供数据科学家验证)
- SageMaker Canvas is integrated with Amazon SageMaker Studio, making it easier for business analysts to share models and datasets with data scientists so they can validate and further refine the ML model.
收费方式
收费挺贵的,按照数据cell(行 x 列)的方式计费,50万条记录,26个字段,40个小时使用时长,最终花费会达到421美元。